
PHD
Personalized 3D Human Body Fitting with Point Diffusion
ICCV 2025
 2ETH AI Center
2ETH AI Center
 3Meta
3Meta
Listen to NotebookLM summary:
TL;DR
- We introduce a new paradigm of personalized 3D pose estimation tailored for future perceptive AI.
- We design an approach, SHAPify, for calibrating personal shape information from 2D images.
- We propose PointDiT, a novel point diffusion model for 3D pose fitting leveraging personal shape conditions.
- Our method is a plug-and-play module that can enhance the performance of existing 3D pose estimators.
Abstract
We introduce PHD, a novel approach for personalized 3D human mesh recovery (HMR) and body fitting that leverages user-specific shape information to improve pose estimation accuracy from videos. Traditional HMR methods are designed to be user-agnostic and optimized for generalization. While these methods often refine poses using constraints derived from the 2D image to improve alignment, this process compromises 3D accuracy by failing to jointly account for person-specific body shapes and the plausibility of 3D poses. In contrast, our pipeline decouples this process by first calibrating the user's body shape and then employing a personalized pose fitting process conditioned on that shape. To achieve this, we develop a body shape-conditioned 3D pose prior, implemented as a Point Diffusion Transformer, which iteratively guides the pose fitting via a Point Distillation Sampling loss. This learned 3D pose prior effectively mitigates errors arising from an over-reliance on 2D constraints. Consequently, our approach improves not only pelvis-aligned pose accuracy but also absolute pose accuracy -- an important metric often overlooked by prior work. Furthermore, our method is highly data-efficient, requiring only synthetic data for training, and serves as a versatile plug-and-play module that can be seamlessly integrated with existing 3D pose estimators to enhance their performance.
Method
SHAPify
We estimate a person's 3D body shape from a single image in a reference pose. Our method works by minimizing the 2D keypoint reprojection error, given a known camera focal length. To resolve the ambiguity of the unknown camera pitch angle, we regularize the optimization with minimal personal measurements, ensuring an accurate and optimal body shape.
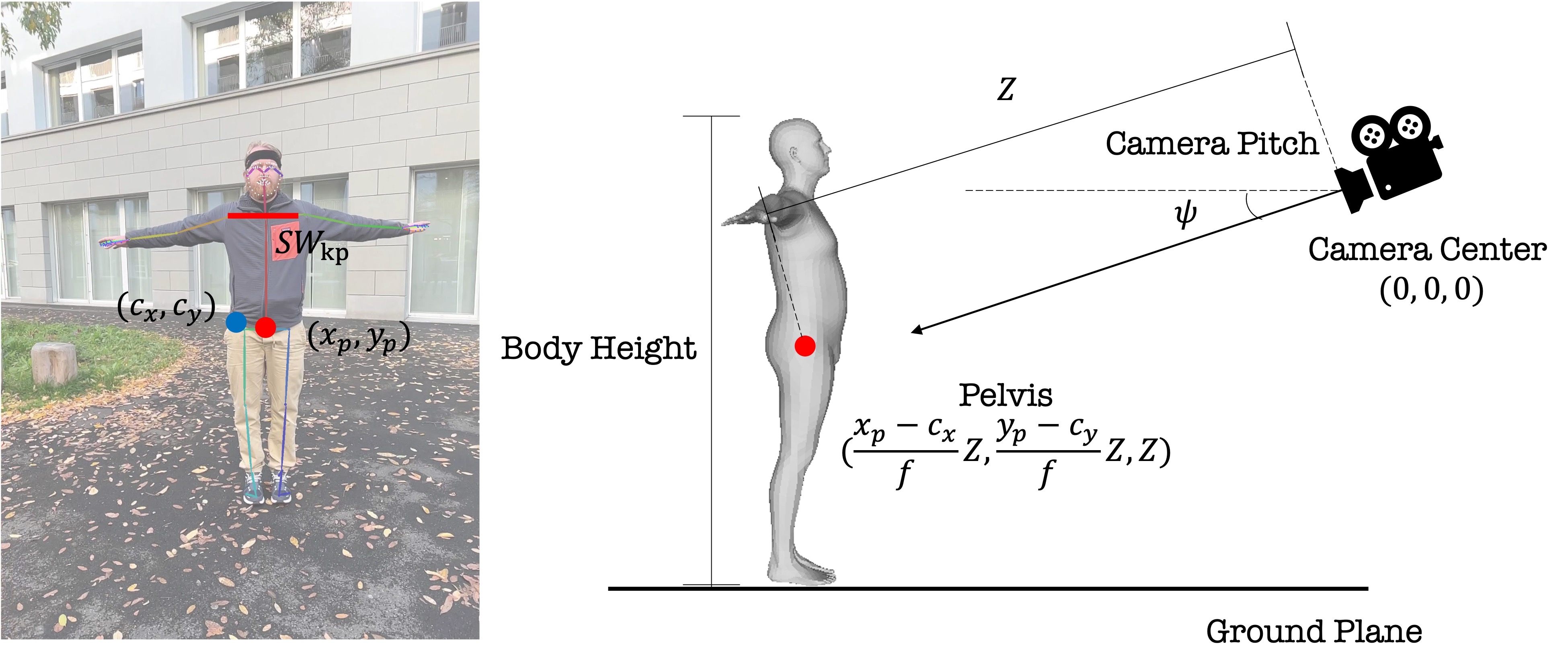
SHAPify estimate a person's 3D body shape from a single image. The problem is ill-posed because the camera pitch angle is unknown. We resolve this by using minimal body height and weight as regularization in the optimization process.
Shape-Conditioned Point Diffusion Transformer
To facilitate personalized 3D pose fitting, we propose PointDiT, a novel point diffusion transformer that generates 3D human poses conditioned on both the input image and the individual's body shape. PointDiT employs a rectified flow formulation to iteratively denoise random point clouds in as few as 5 denoising steps. This approach enables the generation of plausible 3D poses that align well with the observed 2D data while respecting the unique body shape of the individual.
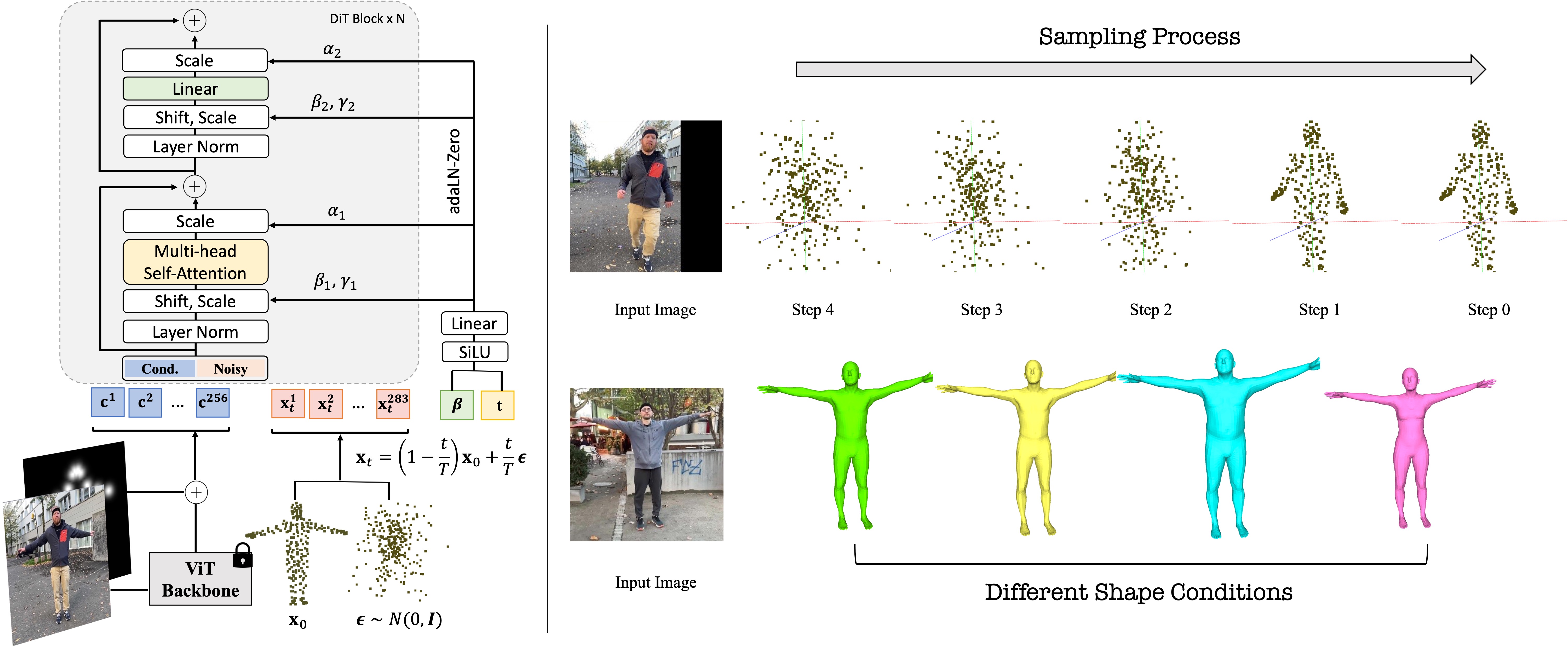
PointDiT is a novel point diffusion transformer leveraging the rectified flow formulation. It samples 3D body surface points by iteratively denoising random point clouds, conditioned on the image tokens and individual's body shape.
Point Distilled Body Fitting
The learned PointDiT model servers as a powerful 3D pose prior for guiding the body fitting and mitigating errors from over-reliance on 2D constraints. Inspired by Score Distillation Sampling, we introduce a Point Distillation Sampling loss that leverages PointDiT to refine 3D pose fitting.
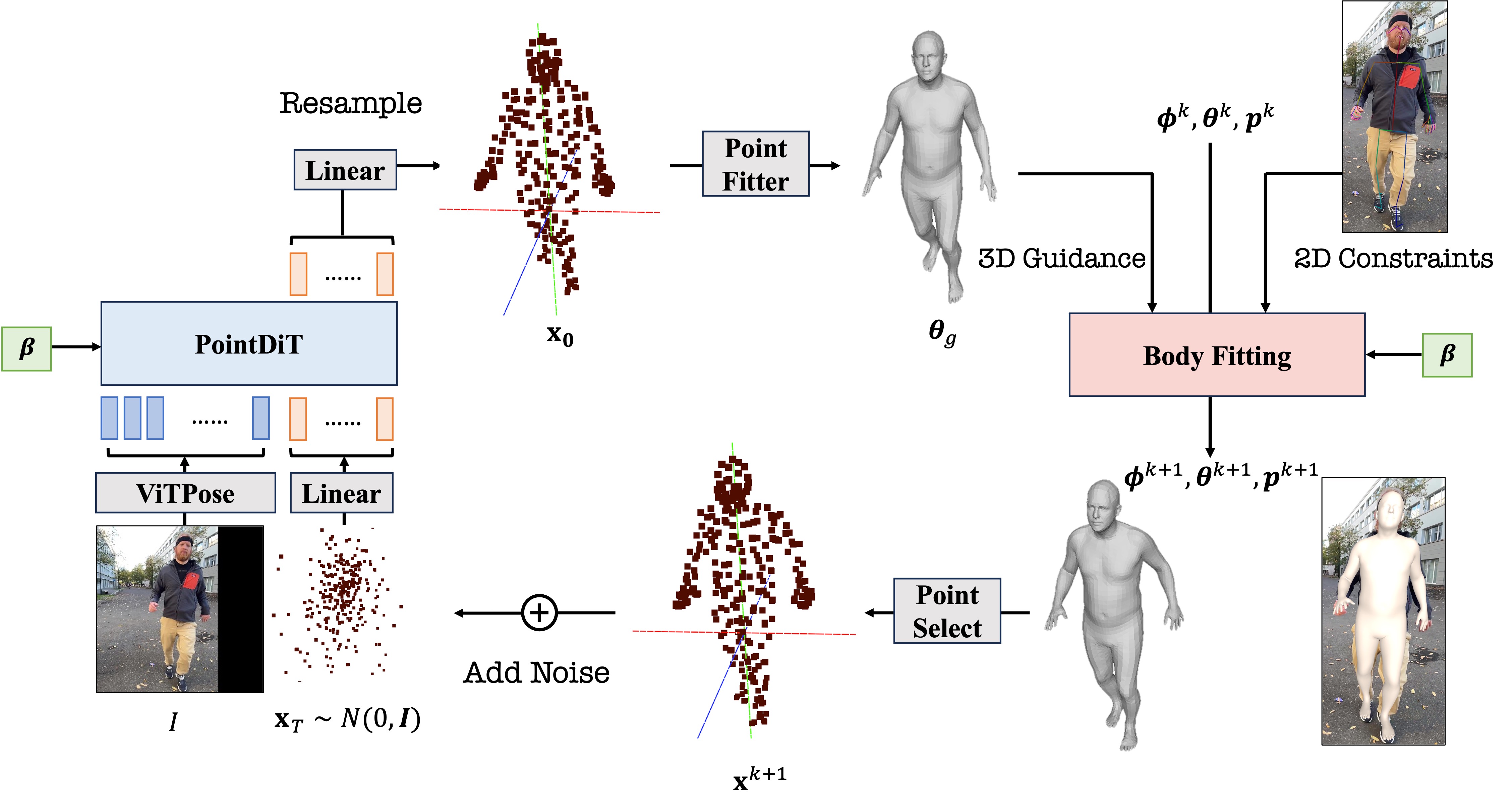
The Point Distillation Sampling loss guides 3D pose fitting leveraging the capabilities of PointDiT, ensuring the incorporation of personal body shape information and preventing overfitting to 2D keypoints.
Results
3D Pose Fitting Accuracy
We compare our approach to ScoreHMR, a recent diffusion-based pose fitting method which also leverages a body prior but still relies heavily on regressors for initialization.
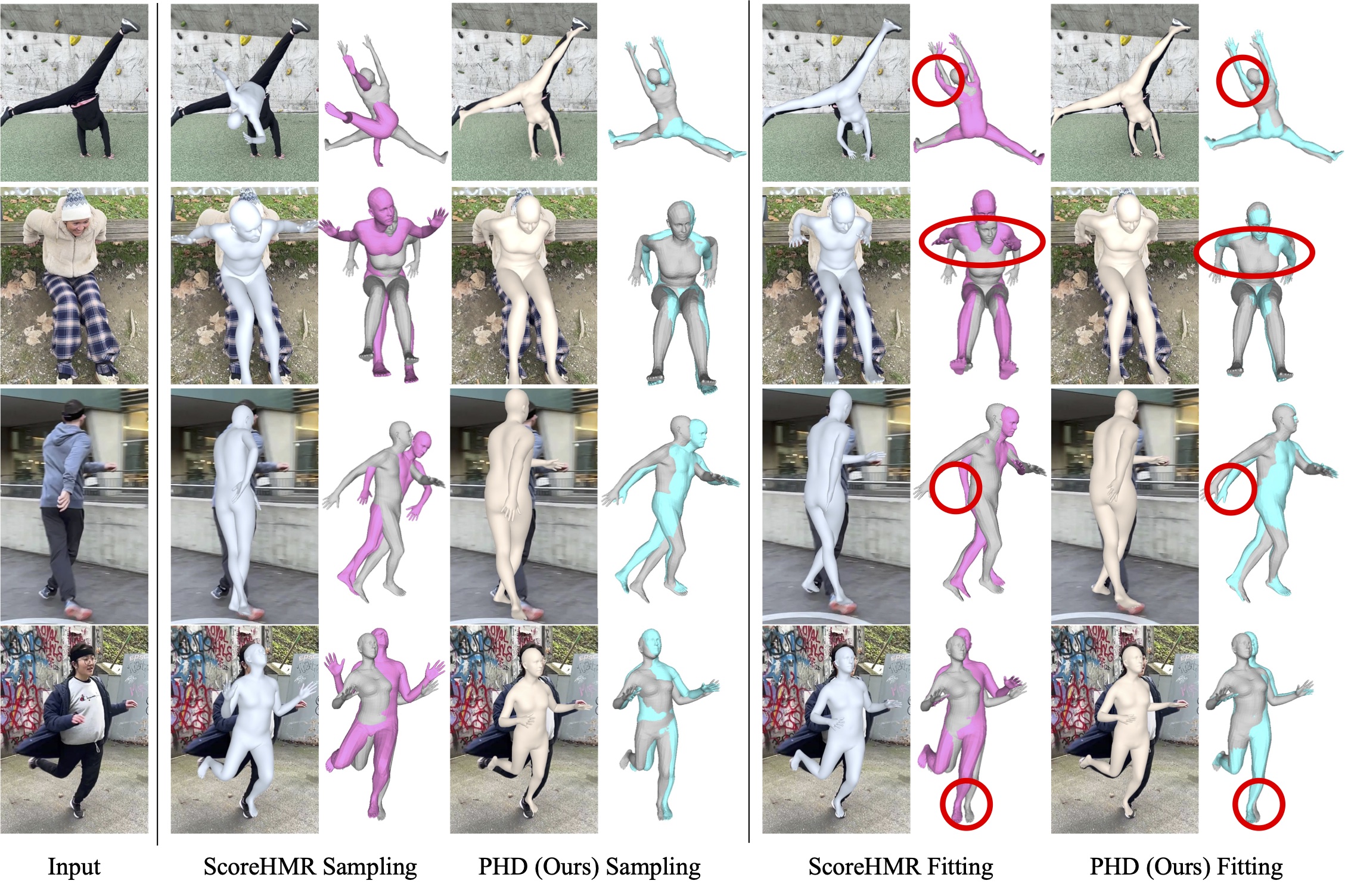
Comparisons of sampling poses and body fitting with ScoreHMR. Our method matches both 2D images and 3D ground truth (grey color meshes) better
While the 2D reprojections of ScoreHMR appear reasonable, it struggles to produce consistent and accurate shapes over time. In 3D view, ScoreHMR also fails to predict correct and stable 3D poses.
References
[1] Stathopoulos et al. (CVPR 2024). Score-Guided Diffusion for 3D Human Recovery.
[2] Patel et al. (3DV 2025). CameraHMR: Aligning People with Perspective.
[3] Goel et al. (ICCV 2023). Humans in 4D: Reconstructing and Tracking Humans with Transformers.
[4] Choutas et al. (CVPR 2022). Accurate 3D Body Shape Regression using Metric and Semantic Attribute.
[5] Black et al. (CVPR 2023). BEDLAM: A Synthetic Dataset of Bodies Exhibiting Detailed Lifelike Animated Motion.
[6] Kocabas et al. (ICCV 2021). SPEC: Seeing People in the Wild with an Estimated Camera.
Citation
If you find our work useful, please consider citing: